Description
Models for conversational question answering (ConvQA) over knowledge graphs (KGs) are usually trained and tested on benchmarks of gold QA pairs. This implies that training is limited to surface forms seen in the respective datasets, and evaluation is on a small set of held-out questions. Through our proposed framework REIGN, we take several steps to remedy this restricted learning setup. First, we systematically generate reformulations of training questions to increase robustness of models to surface form variations. This is a particularly challenging problem, given the incomplete nature of such questions. Second, we guide ConvQA models towards higher performance by feeding it only those reformulations that help improve their answering quality, using deep reinforcement learning. Third, we demonstrate the viability of training major model components on one benchmark and applying them zero-shot to another. Finally, for a rigorous evaluation of robustness for trained models, we use and release large numbers of diverse reformulations generated by prompting GPT-3.5 for benchmark test sets (resulting in 20x increase in sizes). Our findings show that ConvQA models with robust training via reformulations, significantly outperform those with standard training from gold QA pairs only.
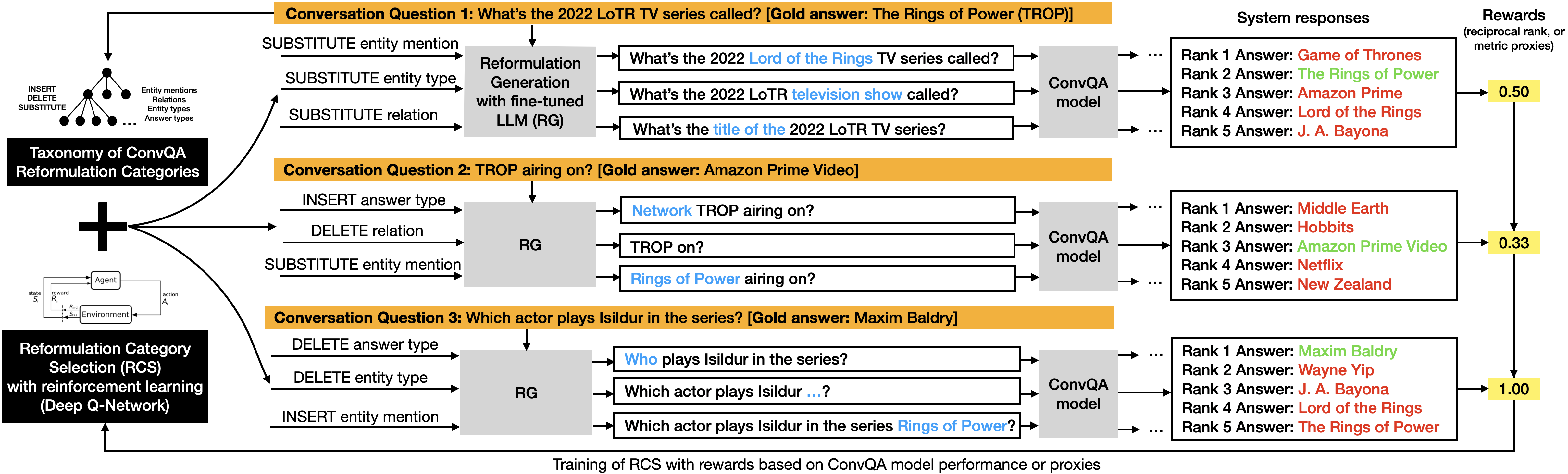
Performance-guided reformulation generation in REIGN
Our method REIGN (REInforced GeNeration) aims to increase the robustness of ConvQA models. It strengthens the model's training by exposing it upfront to a larger variety of intent-preserving surface forms for the same training sample. Examples of such syntactic variations representing the same question semantics are shown in the figure above in orange boxes, perturbed zones in reformulations are in blue. With this more diverse training data, the ConvQA model learns to cope better with different syntactic formulations. Our reformulations are created from first principles. We propose a taxonomy of reformulation categories for ConvQA, that systematically manipulates parts of a given conversational question based on string edit operations. We use BART as our reformulation generation model which is fine-tuned using distant supervision. Given that our generated instances are noisy, it is unlikely that for a given question, all categories of reformulations would improve the ConvQA model's performance. As a result, for each question, we would like to judiciously select a few of these that are most beneficial. So we pass generated reformulations to the QA model we wish to improve, and obtain ranked answer lists as responses - shown in boxes with green (correct) and red (incorrect) answers in the right half of the figure. The model's answer performance metrics (or proxies) are used as rewards (shaded yellow boxes) to train a Reformulation Category Selector (RCS) with Deep Q-Networks, a form of RL that approximates value functions. The trained RCS is then used as a means for model-specific data augmentation: it selects only the top-k reformulations that would be used for additional training data for the QA model for maximum performance improvement.
Download GPT-augmented test data
To enable large-scale evaluation of REIGN and to show the improved robustness of the underlying QA models, we augment the testsets of two existing ConvQA benchmarks (ConvMix and ConvQuestions) with 20 reformulations per original question generated by Chat-GPT (GPT-3.5), resulting in 96k (ConvMix) and 224k (ConvQuestions) test instances.
GPT-ConvMix testset (96k questions) GPT-ConvQuestions testset (224k questions) The testsets are licensed under a Creative Commons Attribution 4.0 International License.
Code on GitHub
REIGN codePaper
"Robust Training for Conversational Question Answering Models via Reinforced Reformulation Generation", Magdalena Kaiser, Rishiraj Saha Roy and Gerhard Weikum, in Proceedings of the 17th ACM International Conference on Web Search and Data Mining (WSDM'24), Merida, Mexico, 04th - 08th March 2024. [Preprint] [Slides] [Poster]Contact
For more information, please contact: Magdalena Kaiser (mkaiser AT mpi HYPHEN inf DOT mpg DOT de), Rishiraj Saha Roy (rishiraj AT mpi HYPHEN inf DOT mpg DOT de) or Gerhard Weikum (weikum AT mpi HYPHEN inf DOT mpg DOT de).
To know more about our group, please visit https://www.mpi-inf.mpg.de/departments/databases-and-information-systems/research/question-answering/.